EMR+OSS:离线计算的存储与计算分离简介

 分类:
分类: 已被围观 11次
已被围观 11次一、背景
在传统Hadoop的使用中,存储与计算密不可分,而随着业务的发展,集群的规模常常不能满足业务的需求。例如,数据规模超过了集群存储能力,业务上对数据产出的周期提出新的要求导致计算能力跟不上。这就要求我们能随时应对集群存储空间不足或者计算能力不足的挑战。
如果将计算和存储混合部署,常常会因为为了扩存储而带来额外的计算扩容,这其实就是一种浪费;同理,只为了提升计算能力,也会带来一段时期的存储浪费。
将离线计算的计算和存储分离,可以更好地应对单方面的不足。把数据全部放在OSS中,再通过无状态的E-MapReduce分析。E-MapReduce只需进行纯粹的计算,不存在存储跟计算搭配来适应业务了,这样最为灵活。
二、架构
离线计算的存储和计算分离架构简单,如下图所示。OSS作为默认的存储,Hadoop/Spark作为计算引擎直接分析OSS存储的数据。

优势
| 因素 | 计算和存储不分离 | 计算和存储分离 |
|---|---|---|
| 灵活性 | 不灵活 | 计算与存储分离后,集群规划简单灵活,基本不需要估算未来业务的规模,做到按需使用。 |
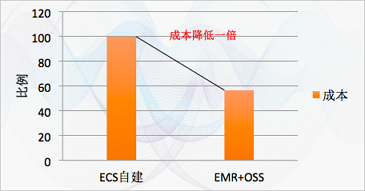
| 成本 | 高 | 在ECS自建的磁盘选择高效云盘,以1 master 8 cpu32g/6 slave 8 cpu32g/10T数据量为例进行估算,存储与计算分离后,成本下降一倍。 |
| 性能 | 较高 | 至多下降10%。 |
三、案例测试
1、测试条件
详细的测试代码请参见GitHub。
集群规模:1 master 4cpu 16g、8 Slave 4cpu 16g、每个slave节点250G*4 高效云盘
Spark测试脚本如下所示。
/opt/apps/spark-1.6.1-bin-hadoop2.7/bin/spark-submit --master yarn --deploy-mode cluster --executor-memory 3G --num-executors 30 --conf spark.default.parallelism=800 --class com.github.ehiggs.spark.terasort.TeraSort spark-terasort-1.0-jar-with-dependencies.jar /data/teragen_100g /data/terasort_out_100g
2、测试结果
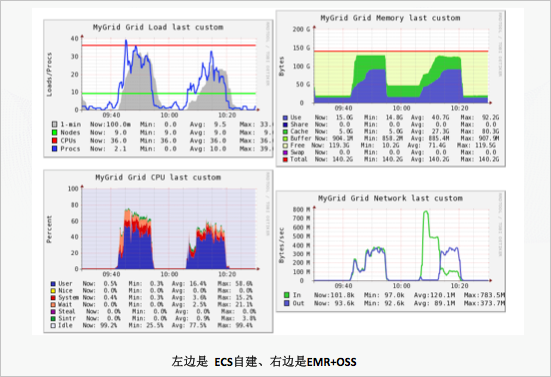
a.性能
b.成本
c.时间

3、结果分析
从性能图上看,EMR+OSS相较于ECS自建Hadoop,有如下优势:
整体的负载更低。
内存利用率基本一样。
CPU使用低,其中iowait与sys低很多。因为ECS自建有datanode及磁盘操作,需要占一些资源,增加CPU的开销。
从网络看,因为sortbenchmark有两次读取数据,第一次是采样,第二次是真正的读取数据,开始网络比较高,随后shuffle+输出结果阶段,网络比ECS自建Hadoop低一半左右。因此从网络来看,整体使用量基本持平。
综上所述,EMR+OSS比自建ECS使用更少的资源,成本节约了一半,但是性能下降基本可以忽略不计。并且,如果提高EMR+OSS的并发度,则时间上有可能比ECS自建Hadoop集群更有优势。
四、不适用的场景
以下场景不建议使用EMR+OSS:
1、小文件过多的场景。
如果文件小于10M时,请合并小文件。当数据量在128M以上时,使用EMR+OSS的性能最佳。
2、频繁操作OSS元数据的场景。
以上就是EMR+OSS:离线计算的存储与计算分离简介说明,阿里云代理商凯铧互联提供阿里云服务器/企业邮箱等产品的代购服务,同样的品质,更多贴心的服务,更实惠的价格。 阿里云代理商凯铧互联会为您提供一对一专业全面的技术服务,同时还能为您提供阿里云其他产品购买的专属折扣优惠。通过凯铧互联购买可以获得折上折优惠!若您需要帮助可以直接联系我方客服,阿里云代理商凯铧互联专业技术团队为您提供全面便捷专业的7x24技术服务。 电话专线:136-5130-9831,QQ:3398234753。
长期稳定+永久朋友(10年分销)

产品列表

本公司部分客户(无排名)









